
* 본포스팅은 <트랜스포머로 시작하는 자연어 처리>에서 발췌한 내용으로 작성되었습니다.
✔ 트랜스포머란무엇인가?
트랜스포머는 산업적인 단일화(homogenized)된 포스트-딥러닝(post-deep learning)1 모델로, 슈퍼 컴퓨터가 병렬로 처리할 수 있게 고안됐다. 트랜스포머의 단일화된 특성 덕분에 별도 미세 조정없이도 다양한 작업에 모델을 활용할 수 있고, 수십억 파라미터로 라벨링되지 않은 수십억 원시데이터(raw data)에 대해 자기 지도 학습(self-supervised learning)을 수행할 수 있다. 포스트 딥러닝의 이와 같은 아키텍처를 파운데이션 모델(foundation model) 이라고 한다.
2015년도에 시작된 4차 산업혁명은 모든 것을 연결함으로써 기계 간 자동화를 실현했다. 파운데이션 모델인 트랜스포머는 4차 산업혁명을 대표한다. 인공지능 전반에서, 특히 자연어 처리(NLP, Natural Language Process)에서 전통적인 과거 소프트웨어 보다 비약적 발전을 이뤘다. 5년도 채 지나지 않아, AI는 효과적인 클라우드 서비스로 자리 잡았다. 과
거와 같이 로컬(local) 환경에서 라이브러리들을 다운로드하여 개발하는 형태는 이제 교과서 연습문제에서나 보일 뿐, 현업에서는 클라우드 환경에서 개발하는것이 일반적이다. 4차 산업 시대의 프로젝트 매니저는 OpenAI 클라우드 플랫폼에 접속하여 가입하고 API Key를 얻어 몇 분 안에 작업을 시작할 수 있다. 해당 서비스의 사용자는 원하는 NLP 작업을 선택하고 분석하고자 하는 문장을 입력하여 결과를 받아볼 수 있다. 또한, GPT-3 코덱스(Codex)와 같은 서비스를 이용해 프로그래밍 지식 없이도 애플리케이션을 만들 수 있다. 이런 상황에 태어난 신기술이 바로 프롬프트 엔지니어링(prompt engineering)이다. 물론 GPT-3가 적합하지 않은 작업도 있으며, GPT-3를 적용하기 힘들 때 프로젝트 매니저, 컨설턴트, 개발자 등은 구글 AI, Amazon Web Services(AWS),앨런 인공지능 연구소(Allen Institute for AI), 허깅페이스(Hugging Face)에서 제공하는 다른 시스템을 사용할 수 있다. 그렇다면 프로젝트 매니저는 로컬에서 개발해야 할까?
아니면 구글 클라우드(Google Cloud), 마이크로소프트 애저(Microsoft Azure), 혹은 아마존 웹 서비스(AWS) 상에서 직접 개발해야 할까? 개발팀이 허깅페이스나 구글 트랙스(Google Trax), OpenAI, AllenNLP를 선택해야 할까? 인공지능 전문가나 데이터 과학자는 실질적인 AI 개발이 필요없는 서비스형 API를 사용해야 할까?
✔ 트랜스포머로 NLP 모델 최적화
수십 년 동안 NLP 시퀀스 모델에 LSTM을 포함한 순환 신경망(RNN, Recurrent Neural Networks)을 적용해 왔다. 그러나 긴 시퀀스와 많은 파라미터에 직면하면 순환 신경망의 순환부는 한계에 도달한다. 따라서 첨단 트랜스포머가 대세가 됐다.
이 섹션에서 트랜스포머로 이어진 NLP의 간략한 배경을 살펴보자. 트랜스포머 모델 아키텍처는 2장.트랜스포머 모델 아키텍처 살펴보기에서 살펴보자. 먼저 NLP 신경망의 RNN 층을 대체한 트랜스포머의 어텐션 헤드(attention head)를 직관적으로 살펴보자.
트랜스포머 핵심 개념을 대략적으로 요약하면 “토큰을 섞는 것”이라 할 수 있다. NLP 모델은 먼저 단어 시퀀스를 토큰으로 변환한다. RNN은 토큰들을 순환부(recurrent functions)에서 분석한다. 트랜스포머는 각 토큰을 시퀀스에 존재하는 다른 토큰들과 연관시킨다. 아래 그리을 보자
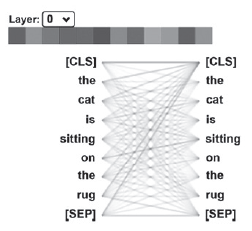
2장에서 어텐션 헤드를 자세히 살펴볼 것이다. 그림 1.3의 핵심은 시퀀스의 각 단어(토큰)는 동일 시퀀스의 다른 모든 단어와 연관되어 있다는 점이다. 이 모델이 4차 산업혁명인 NLP로 가는 문을 열어준다. 트랜스포머의 배경에 대해 간단히 살펴보자.
트랜스포머의 배경
많은 천재들이 지난 100년 이상 동안 시퀀스 패턴 및 언어 모델링을 연구해 왔다. 그 결과 기계는 가능한 단어 시퀀스를 예측하는 방법을 점진적으로 학습할 수 있었다. 이를 가능하게 한 거인들을 모두 인용하려면 책 한 권 분량이 될 것이다. 이 섹션에서는 트랜스포머 등장 근거를 소개하기 위해 필자가 가장 좋아하는 연구자들을 독자에게 소개하겠다.
20세기 초, 안드레이 마르코프(Andrey Markov)는 무작위 값(random values) 개념을 도입하고 확률적 프로세(stochastic processes) 이론을 만들었다. AI에서 우리는 이를 마르코프 의사 결정과정(Markov Decision Process, MDP), 마르코프 체인(Markov Chains), 마르코프 프로세스(Markov Processes)라 부른다. 20세기 초, 마르코프는 시퀀스의 마지막 요소만으로 다음 요소 예측이 가능하다는 것을 보였다. 그는 수천 개의 문자들을 포함하는 과거 시퀀스 데이터셋에 자신의 기법을 적용하여 문장의 다음 문자를 예측했다. 기억할 점은 그는 컴퓨터가 없었음에도 오늘날 인공지능 분야에서 여전히 사용하는 이론을 증명했다는 점이다. 1948년, 클로드 섀넌(Claude Shannon)이 「통신의 수학적 이론(The Mathematical Theory of Communication)」을 발간했다. 클로드 섀넌은 소스 인코더(source encoder), 수신기(transmitter), 시 맨틱 디코더(semantic decoder) 기반의 통신 모델 근거를 마련했다.
그는 오늘날 우리가 알고 있는 정보 이론(Information Theory)을 창안했다. 1950년, 앨런 튜링(Alan Turing)이 「컴퓨팅 기계와 지능(Computing Machinery and Intelligence)」 논문을 발간했다. 앨런 튜링은 2차 세계대전 중 독일군의 암호화된 메시지를 해독한 튜링 머신의 성공을 바탕으로 기계 지능에 대해 설명했다. 메시지는 단어와 숫자의 시퀀스로 이뤄져 있었다. 1954년, 조지타운-IBM 실험에서 컴퓨터로 규칙 시스템(rule system)을 사용한 번역 실험을 했다. 러시아어 문장을 영어로 번역한 실험이었다. 규칙 시스템은 언어 구조를 분석하는 규칙 목록을 실행하는 프로그램이다. 오늘날에도 규칙 시스템은 어디에나 존재한다. 그러나 경우에 따라서는 인공지능이 수십억 개의 언어 조합에 대한 규칙 목록을 자동으로 학습하여 규칙 목록을 대체할 수 있다. 1956년, 기계가 학습할 수 있다는 사실이 밝혀지면서 존 매카시(John McCarthy)가 “인공지능”이라는 표현을 처음 사용했다.
1982년, 존 홉필드(John Hopfield)는 홉필드 네트워크(Hopfield networks) 또는 “연관”(associative) 신경망으로 알려진 RNN을 소개했다. 존 홉필드는 1974년 수십 년간 학습 과정 이론적 토대를 마련한 『뇌에 지속적 상태 존재성(The existence of persistent states in the brain)』을 저술한 W.A. Little로부터 영감을 받았다. RNN은 진화했고 오늘날 우리가 알고 있는 LSTM이 등장했다.
아래 그림에서 볼 수 있듯이 RNN은 시퀀스의 지속 상태(persistent states)를 효율적으로 기억한다.

각 상태 은 의 상태를 포착한다. 네트워크의 끝에 도달하면 함수 가 트랜스덕션(transduction)4, 모델링, 그리고 기타 시퀀스 기반 작업을 수행할 것이다. 1980년대에 얀 르쿤(Yann LeCun)은 다목적 컨볼루션 신경망(Convolutional Neural Network, CNN)을 설계했다. 그는 텍스트 시퀀스에 CNN을 적용했다. 오늘날 시퀀스 트랜스덕션 및 모델링에도 CNN이 적용된다. CNN 또한 정보를 계층별로 처리하는 W.A Little의 지속적 상태를 기반으로 한다. 1990년대에 얀 르쿤은 수년간의 작업을 요약하여 오늘날 우리가 알고 있는 많은 CNN 모델을 낳은 LeNet-5를 개발했다. 그러나 CNN의 효율적인 아키텍처는 길고 복잡한 시퀀스에서 장기 의존성5 처리 시 문제가 발생한다. 그 외 AI 전문가라면 누구나 인정할 만한 훌륭한 이름, 논문, 모델을 더 언급할 수 있다. 지난 몇년 동안 AI 분야에서 모두가 올바른 방향으로 나아가고 있는 것처럼 보였다. 마르코프 필드, RNN, CNN은 여러 다른 모델로 발전했다. 마지막 토큰뿐만 아니라 시퀀스 내의 다른 토큰도 살펴보는 어텐션 개념이 등장했다. 어텐션 개념은 RNN과 CNN 모델에 추가됐다. 그 후, AI 모델이 컴퓨팅 성능을 더 요구하는 긴 시퀀스를 분석해야 하는 경우 AI 개발자는 더 강력한 컴퓨터를 사용하고 파라미터를 최적화하는 방법을 찾았다.
시퀀스-투-시퀀스(sequence-to-sequence) 모델 연구가 일부 있었지만 기대에 미치지 못했다. 더 이상 진전을 이루기 위해 할 수 있는 일은 없는 것처럼 보였다. 그렇게 30년이 흘렀다. 그러다 2017년 말부터 산업화된 어텐션 헤드 서브 층 등을 갖춘 최첨단 트랜스포머가 등장했다. RNN은 더 이상 시퀀스 모델링에 꼭 필요해 보이지 않았다.

《트랜스포머로 시작하는 자연어 처리》
'IT 정보' 카테고리의 다른 글
| [트랜스포머로 시작하는 자연어 처리] 트랜스포머 용어 정리 (0) | 2024.07.16 |
|---|---|
| [C 언어] 변수의 사용 영역 (0) | 2024.06.12 |
| [C 언어] 매개변수와 반환값을 사용하는 함수 (1) | 2024.06.10 |



